Benchmarking Simulation-Based Inference
Many domains of science make use of numerical simulators for which (1) it is easy to simulate but (2) the likelihood is unavailable, making it hard to perform statistical identification of model parameters consistent with observed data. Simulation-based inference (SBI) deals with this 'likelihood-free' setting. Although recent advances have led to a large number of SBI algorithms, a public benchmark for such algorithms has been lacking: We set out to fill this gap, carefully select tasks and metrics, and evaluate several canonical algorithms. Through this website you can explore all results of our manuscript, including comparisons on all metrics and plotting of posteriors for each of more than 10 000 runs.
Keep reading for a brief summary of the manuscript, or jump right into interactive results (through the menu on top). We provide a framework to benchmark your own algorithms, code and results for reproducibility, and invite contributions.
Our Motivation and Methods
Open benchmarks can be an important component of transparent and reproducible computational research. However, a benchmark framework for SBI has been lacking, possibly due to the challenging endeavour of designing benchmarking tasks and defining suitable performance metrics.
We selected a set of initial algorithms representing four distinct approaches to SBI, analyzed multiple performance metrics which have been used in the literature, and implemented ten tasks, including ones popular in the field.
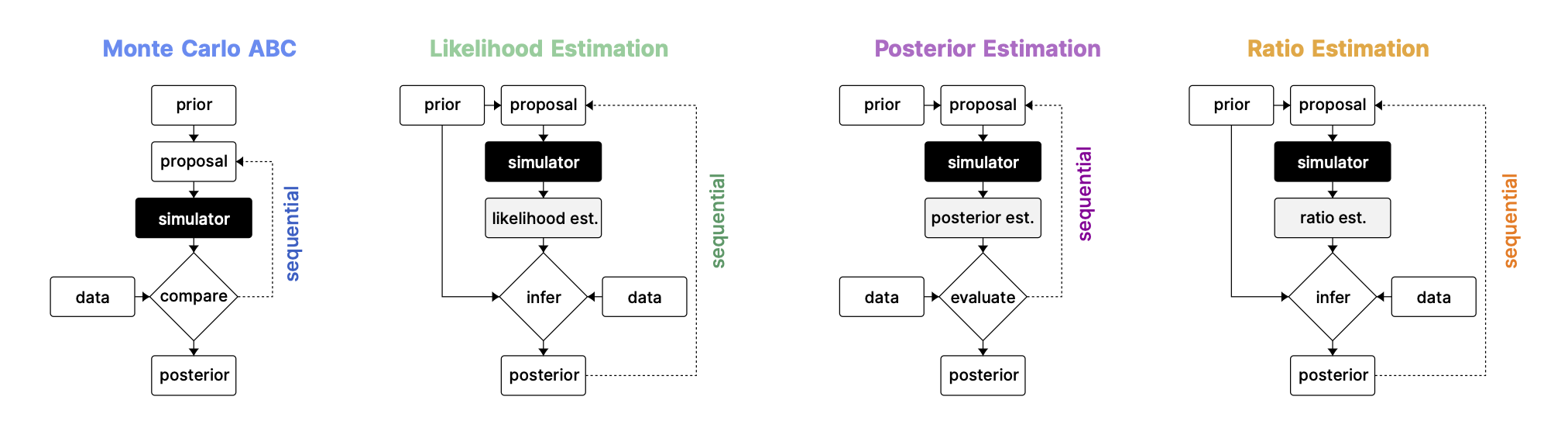
Overview of algorithms. Classification and schemes following Cranmer et al. (2020).
Algorithms. We compare algorithms belonging to four distinct approaches to SBI: Classical ABC approaches as well as model-based approaches approximating likelihoods, posteriors, or density ratios. We contrast algorithms that use the prior distribution to propose parameters against ones that sequentially adapt the proposal. Keeping our initial selection of algorithms focused allowed us to carefully consider implementation details and hyperparameters.
Metrics. The shortcomings of commonly used metrics (see paper for details) led us to focus on tasks for which a likelihood can be evaluated, which allowed us to calculate reference (‘ground-truth’) posteriors. These reference posteriors are made available to allow rapid evaluation of SBI algorithms. While we compare algorithms in terms of classifier 2-sample tests (C2ST) in the paper, the website allows comparisons in terms of all metrics we considered.
Tasks. We focused on eight purely statistical problems and two problems relevant in applied domains, with diverse dimensionalities of parameters and data.
Key Findings
The full potential of the benchmark will be realized when it is populated with additional community-contributed algorithms and tasks. However, our initial version already provides useful insights:
- the choice of performance metric is critical (commonly used metrics such as the likelihood of true parameters or Maximum Mean Discrepancy with median heuristic have important shortcomings);
- the performance of the algorithms on some tasks leaves substantial room for improvement;
- sequential estimation generally improves sample efficiency;
- for small and moderate simulation budgets, neural-network based approaches outperform classical ABC algorithms, confirming recent progress in the field;
- but that there is no algorithm to rule them all.
The performance ranking of algorithms is task-dependent, pointing to a need for better guidance or automated procedures for choosing which algorithm to use when. In the manuscript, we included some considerations and recommendations for practitioners, based on our current results and understanding, and dedicated a page to discussing various limitations.
Find out more in our manuscript, available through PMLR or:
We believe that the full potential of the benchmark will be revealed as more researchers participate and contribute. In order to facilitate this process, we provide a benchmarking framework which is designed to be highly extensible and easily used. See Code & Reproducibility for explanations and examples.
3-Minute Summary
Citation
@InProceedings{lueckmann2021benchmarking,
title = {Benchmarking Simulation-Based Inference},
author = {Lueckmann, Jan-Matthis and Boelts, Jan and Greenberg, David and Goncalves, Pedro and Macke, Jakob},
booktitle = {Proceedings of The 24th International Conference on Artificial Intelligence and Statistics},
pages = {343--351},
year = {2021},
editor = {Banerjee, Arindam and Fukumizu, Kenji},
volume = {130},
series = {Proceedings of Machine Learning Research},
month = {13--15 Apr},
publisher = {PMLR}
}
Support
This work was supported by the German Research Foundation (DFG; SFB 1233 PN 276693517, SFB 1089, SPP 2041, Germany’s Excellence Strategy – EXC number 2064/1 PN 390727645) and the German Federal Ministry of Education and Research (BMBF; project ’ADIMEM’, FKZ 01IS18052 A-D).